Table Of Contents
- 6. Mathematical notes
Here mathematical notes are kept.
Contents
Abstract:
This document is about using Latex in reStructuredText and Sphinx. At the link below there is a introduction to mathematical symbols in Latex.
There are 2 ways of writing math in restructuredText:
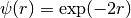 in the text write :math:`\psi(r) = \exp(-2r)`
Inside the back-tics (`) any Latex code can be written. There must be no
space between :math: and the first back-tic.
in the text write :math:`\psi(r) = \exp(-2r)`
Inside the back-tics (`) any Latex code can be written. There must be no
space between :math: and the first back-tic.For producing more complex math like eg an equation* environment in a LaTeX document write:
.. math::
\psi(r) = e^{-2r}
you will get:
Warning
The math markup can be used within reST files (to be parsed by Sphinx) but within your python’s docstring, the slashes need to be escaped ! :math:`\alpha` should therefore be written :math:`\\alpha` or put an “r” before the docstring
Below are some examples of Latex commands and symbols:
To do square roots like eg 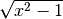 use :math:`\sqrt{x^2-1}`.
use :math:`\sqrt{x^2-1}`.
To do fractions like eg 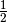 use :math:`\frac{1}{2}`.
use :math:`\frac{1}{2}`.
In order to insert text into a formula use :math:`k_{\text{B}}T` to get
like in 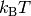
Use \left and \right for before brackets like in
:math:`\left(\frac{1}{2}\right)^n` to get 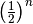 .
.
Displayed math can use \\ and & for line shifts and alignments, respectively.
.. math::
a & = (x + y)^2 \\
& = x^2 + 2xy + y^2
The result is:
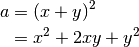
The matrix environment can also contain \\ and &. To get like:
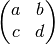
write:
.. math::
\left(\begin{matrix} a & b \\
c & d \end{matrix}\right)
Equations are labeled with the label option and referred to using:
:eq:`label`
E.g:
(1)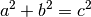
See equation (1)
is written like:
.. math::
:label: pythag
a^2 + b^2 = c^2
See equation :eq:`pythag`
Note that:
- No spaces in label name
- There should be a blank line before the actual latex code
- There should be a space between :label: and the label name
- When referred to label name should be surrounded by `
Abstract:
This chapter is about splines in Scipy and how they can be used for yield curve calculations.
It is shown that splines in scipy is probably b-splines. These splines gives different (but not nessacerily wrong) values when interpolating.
This information is important when using splines from scipy.
The natural cubic spline is already implemented in decimalpy
In order to redo the calculations below you need to install and import the package decimalpy.
>>> import decimalpy as dp
The example will be taken from [Kiusalaas] p. 119. The data are:
>>> x_data = dp.Vector([1, 2, 3, 4, 5])
>>> y_data = dp.Vector([0, 1, 0, 1, 0])
And the natural cubic spline function is instantiated by:
>>> f = dp.NaturalCubicSpline(x_data, y_data)
And the it is possible to do calculations like function values:
>>> print f(1.5), f(4.5)
0.7678571428571428571428571427 0.7678571428571428571428571427
Slopes:
>>> print f(1.5, 1), f(4.5, 1)
1.178571428571428571428571429 -1.178571428571428571428571428
and curvatures:
>>> print f(1.5, 2), f(4.5, 2)
-2.142857142857142857142857142 -2.142857142857142857142857143
and it is quite easy to do a plot:
>>> import matplotlib.pyplot as plt
>>> linspace = lambda start, stop, steps: dp.Vector([(stop - start) / (steps - 1) * i + start for i in range(steps)])
>>> xnew = linspace(1, 5, 40)
>>> x0, spread = 2, 0.5
>>> x2new = linspace(x0 - spread, x0 + spread, 40)
>>> f0x0, f1x0, f2x0 = f(x0, 0), f(x0, 1), f(x0, 2)
>>> f0Lst = dp.Vector([f(x) for x in xnew])
>>> f1Lst = dp.Vector([f0x0 + f1x0 * (x - x0) for x in x2new])
>>> f2Lst = dp.Vector([f0x0 + f1x0 * (x - x0) + f2x0 * (x - x0)**2 / 2 for x in x2new])
>>> plt.plot(x_data, y_data, 'o', xnew, f0Lst, '-', x2new, f1Lst, '-', x2new, f2Lst, '-')
>>> plt.legend(['data', 'fitted f', 'tangent', '2. order'], loc='best')
>>> plt.show()
like:
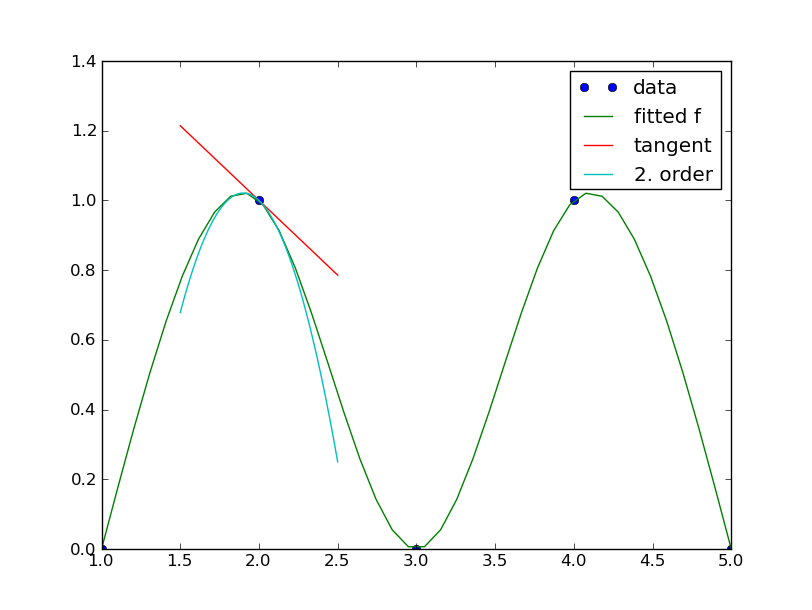
On the other hand [scipy] is well equipped with spline functionality
First set up scipy and numpy:
>>> from numpy import linspace, array, float64
>>> from scipy.interpolate import InterpolatedUnivariateSpline as spline
Use the same data as before:
>>> x_data = array([1, 2, 3, 4, 5], float64)
>>> y_data = array([0, 1, 0, 1, 0], float64)
Creating the cubic spline function:
>>> cubic = spline(x_data, y_data, k=3)
And calculate the cubic spline at 1.5 and 4.5:
>>> cubic(1.5)
array(1.1250000000000002)
>>> cubic(4.5)
array(1.1250000000000002)
This isn’t the same value as before (0.767857142857).
And if one uses interp1d from scipy.interpolate to get the function cubic2:
>>> from numpy import linspace, array, float64
>>> from scipy.interpolate import interp1d
>>> cubic2 = interp1d(x_data, y_data, kind='cubic')
Using cubic2 one gets:
>>> cubic2(1.5)
array(1.1944444444444462)
>>> cubic2(4.5)
array(1.1944444444444466)
Again a new set of values. What is a bit surprising is that a third set of values appears.
So to check the functions in a graph I do:
>>> xnew = linspace(1, 5, 40)
>>> import matplotlib.pyplot as plt
>>> plt.plot(x_data, y_data, 'o', xnew, f0Lst, '-', xnew, cubic(xnew), '--', xnew, cubic2(xnew), '+-')
>>> plt.legend(['data', 'natural spline', 'cubic', 'cubic2'], loc='best')
>>> plt.draw()
to get the graph:
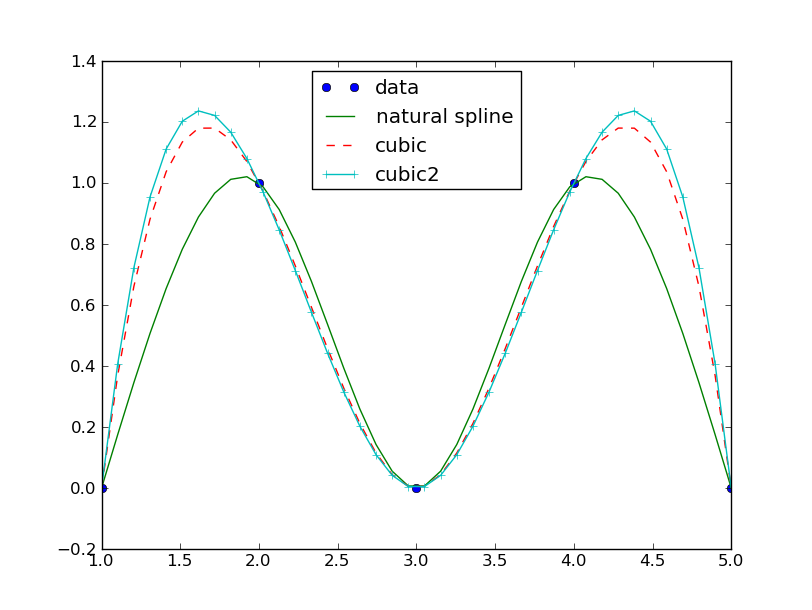
And now it is obvious that scipy isn’t using the natural spline as cubic spline.
What kind of spline is used in scipy? Their code is build upon FITPACK by P. Dierckx.
The main reference is [Dierckx] which is all about b-splines. So a fair guess is that scipy also is b-splines.
This isn’t necessarily bad. Actually I haven’t looked into the differences between the 2 scipy interpolations.
Conclusion:
It matters what kind of interpolation one uses.
The difference in values is probably due to different derivations of (cubic) splines where scipy interpolation is based on b-splines.
Abstract:
This chapter is about derivation of cubic splines and the use of cubic splines for yield curve calculation.
Assume n points 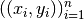 and n curvatures
and n curvatures
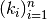 at each point.
at each point.
To ease notation we introduce:
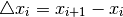
The point are known, the curvatures are assumed known
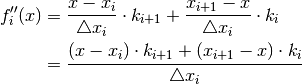
Because we want to evaluate f,f’,f’’ at 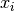 it makes things easier
when they are formulated as functions of
it makes things easier
when they are formulated as functions of 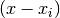 and
and
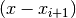 . Eg it is quite simple to see that:
. Eg it is quite simple to see that:
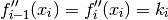
So the second derivative is continous and piecewise linear.
Also the first derivative f’ can be formulated as (since
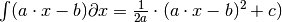 :
:
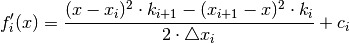
The function 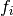 which lies and
which lies and 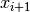 for
for
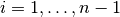 must look like (integrating twice):
must look like (integrating twice):
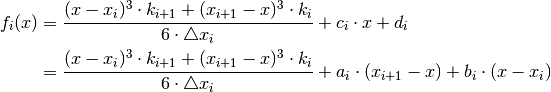
where 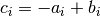 and
and
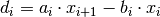 or
or
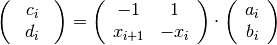
This is possible if the determinant 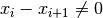 . This is the case
if there isn’t 2 points with the same x-value. An asumption which already must
be in place.
. This is the case
if there isn’t 2 points with the same x-value. An asumption which already must
be in place.
And since f must be continous and go through the points
we have:
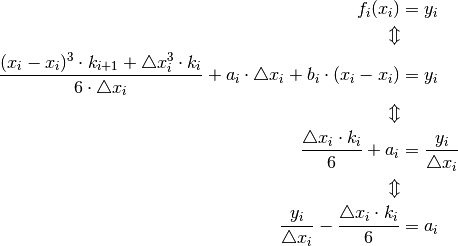
and
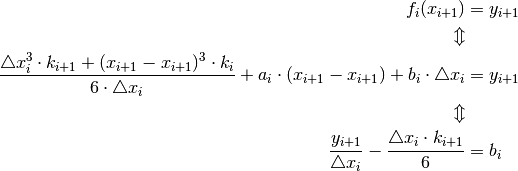
This means that the constant 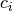 :
:
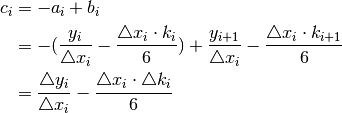
The question is what to do when there is a need for extrapolation. This is a situation quite common when talking about yieldcurve. Eg there are observed zero coupons up until year 20 but a zero coupon for year 25 is needed.
Talking about the natural cubic spline and financial cubic spline they are just linear extrapolations of the endpoints with the same slope as in the endpoints.
The only difference between the 2 cubic splines is that financial cubic spline is set to have a slope equal to zero at the endpoint to the right.
To estimate the curvatures one uses the first order derivatives:
And the assumption that the slopes are continous at the points
, ie
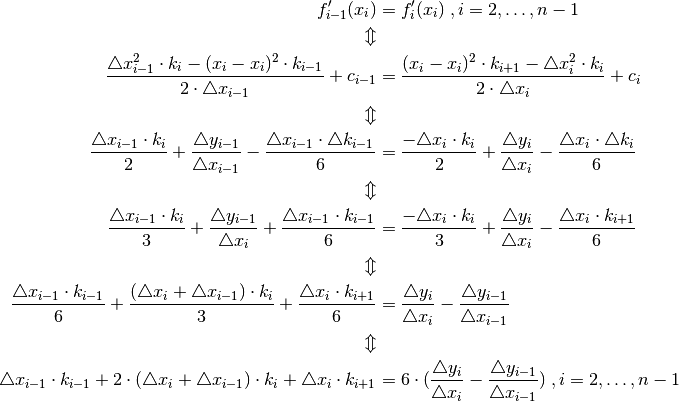
This gives n - 2 linear equations to estimate n curvatures. This means that 2 asumptions are necessary in order to calculate the n curvtures.
Here the asumptions are 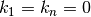 .
The other equations becomes
.
The other equations becomes  :
:
In all n variables 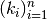 and n linear equations
and n linear equations
Here the asumptions are 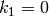 and
and 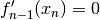 or:
or:
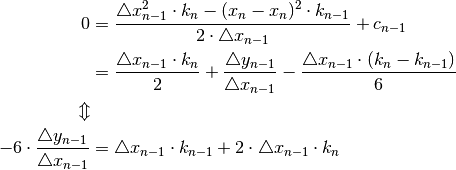
The other equations becomes :
Also here there are in all n variables and n linear
equations
Abstract:
Lagrange Interpolation has had a revelation since the Barycentric formulas were developed.
Here Barycentric Lagrange Interpolation will be examined as a tool for finding weights to approximate the first and second order derivative for a function only known by it’s functional values.
The first order is used for the duration in finance while the second order derivative is used for the convexity.
This section is highly inspired on [BerrutTrefethen], [SadiqViswanath] and [Fornberg].
Also as references [Kiusalaas] and [Ralston] has been invaluable.
First construct a polynomial with n + 1 different grid values
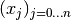 :
:
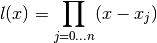
This polynomial has degree n + 1. And it is obvious then that
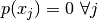 .
.
Consider then the tangent for p in grid value 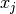 , ie.:
, ie.:
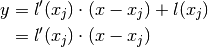
Now define n + 1 polynomials as:
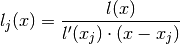
These polynomials all satisfy:
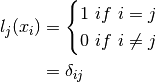
In other words 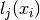 is Kroenecker’s delta.
Note that the
is Kroenecker’s delta.
Note that the 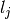 ‘s all have degree n.
‘s all have degree n.
Since 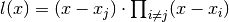 we have:
we have:
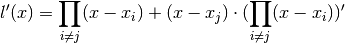
And then when letting the grid values be the argument of l(x) (last part above
is zero since 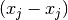 is):
is):
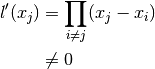
we have that the polynomials 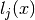 are well defined. This is because
are well defined. This is because
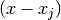 can be shortened out and then the polynomials
are just scaled with a nonzero scaling constants.
can be shortened out and then the polynomials
are just scaled with a nonzero scaling constants.
Definition, Lagrange Interpolation and Remainder:
Consider n + 1 points 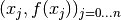 . Then the unique
polynomial of the minimal degree n going through all n + 1 points is:
. Then the unique
polynomial of the minimal degree n going through all n + 1 points is:
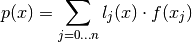
Define 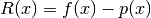 as the Lagrange remainder.
as the Lagrange remainder.
Since is Kroenecker’s delta it is obvious that
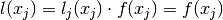 .
.
Theorem, Lagrange Remainder:
Let ![]a, b[](../_images/math/874ae2f4872f8be43c52b3303eda892b350d4f33.png) being an open interval containing all the n+1 grid values
and f is a n+1 times continous differentiable
function on :
being an open interval containing all the n+1 grid values
and f is a n+1 times continous differentiable
function on :
![\forall x \in ]a, b[ \quad \exists \zeta \in ]a, b[:
f(x) &= \sum_{j=0 \dotsc n} l_j(x) \cdot f(x_j)
+ \frac{l(x) \cdot f^{(n+1)}(\zeta)}{(n+1)!} \\
&= p(x) + R(x)](../_images/math/cad27d1e2e4f858cb147aa75cfbc4d817a18047f.png)
For ![x \in ]a,b[](../_images/math/91706221f564011fa2523c11125a8c9904e9569f.png) :
:
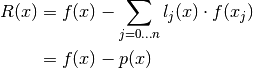
Observe that 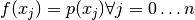 i.e.
i.e. 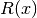 has n+1 zeros.
has n+1 zeros.
Also observe that since p(x) has degree n 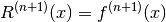 and
and 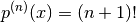 .
.
Now define:
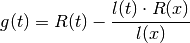
Observe that 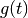 has both and x as
roots, ie n+2 zeros.
has both and x as
roots, ie n+2 zeros.
According to Rolle’s theorem
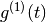 has n+1 zeros and successively
has n+1 zeros and successively 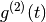 has n zeros.
has n zeros.
So 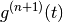 has 1 zero, ie
has 1 zero, ie
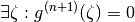 or
or
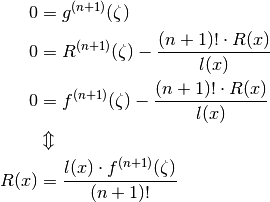
(see also)
Q.E.D.
The Lagrange Remainder can be used to limit the overall accuracy for the Lagrange
Interpolation if the function f(x) is n+1 times continous differentiable on the
closed interval ![[a,b]](../_images/math/8ecbd1ba3da8f2adef66a63f2ab32c47e63fa734.png) .
.
This is because ![\exists M : |f^{(n+1)}(x)| \le M \forall x \in [a,b]](../_images/math/01f964b0650d394675ad2795eabebb7965ef1d51.png) , ie:
, ie:
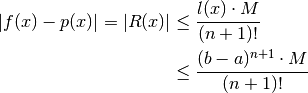
So if 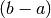 converges to zero then the accuracy becomes of order n+1 ie
converges to zero then the accuracy becomes of order n+1 ie
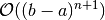 .
.
Observation:
The Lagrange Interpolation can for a set of n+1 grid values
can be seen as a way of interpolating a function
value f(x) based on a weighted average of the functional values
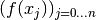 where the weights are
where the weights are
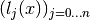 and the accuracy will be of order
.
and the accuracy will be of order
.
This can be taken even further. Since only the weights depends on x the
first order differentiation of 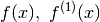 can be approximated
by:
can be approximated
by:
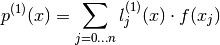
So the first order derivative 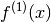 at x can be approximated by
the functional values and the weights are
at x can be approximated by
the functional values and the weights are
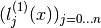 and the accuracy will be of order
and the accuracy will be of order
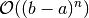 , ie the accuracy loses 1 degree.
, ie the accuracy loses 1 degree.
And successively for the second order derivative:
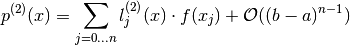
This makes Lagrange Interpolation well suited for finding weighted averages
of functional values for derivatives of any
order with high accuracy,
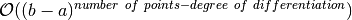 .
.
Computationally Lagrange Interpolation isn’t that effective. But further
analysis shows that the  ‘s all have the same common factor
‘s all have the same common factor
 so we have the First Barycentric formula:
so we have the First Barycentric formula:
(2)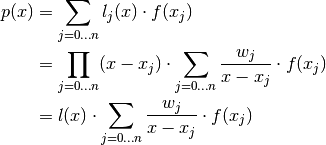
where
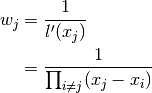
Looking at the constant function 1 gives:
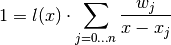
or
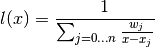
This way we have the Second Barycentric formula:
(3)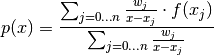
Both formulas shows a remarkable low dependence on the 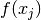 ‘s since a change in one ‘s will have a multiplicative effect only one place.
‘s since a change in one ‘s will have a multiplicative effect only one place.
Interpolation should be done based on the Second Barycentric formula (3).
For updating the weights with an extra point consider a set of basis points
to be used as a basis for Barycentric
Lagrange interpolation.
When a new grid value 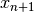 has to be added the algorithm is:
has to be added the algorithm is:
- Calculate
- Calculate
It is obvious that there needs to be minimum 2 values. When there are only 2 grid values 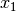 and
and 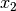 then
then 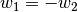 .
.
One of the things to use Barycentric Lagrange interpolation is to evaluate is to differentiate a curve at a point when only a set points are known with a high precision.
Usual formulas are eg, 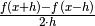 which is
considered as a 3 point estimation based on the points with first coordinate
(x - h, x, x + h).
which is
considered as a 3 point estimation based on the points with first coordinate
(x - h, x, x + h).
The precision or accuracy is here of order 2.
Now consider:
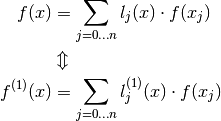
Now according to Second Barycentric formula (3):
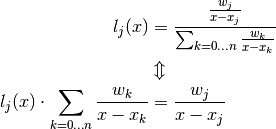
Letting 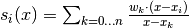 where
where
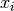 is one of the roots
is one of the roots 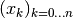 (Important
assumption) we have:
(Important
assumption) we have:
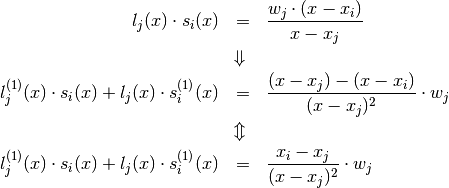
The last equation will be used several times so it gets a number:
(4)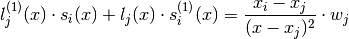
Since by design 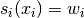 and
and 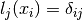 we have for
we have for 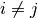 in (4):
in (4):
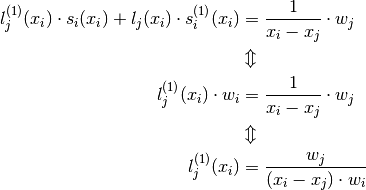
Now for i = j we have:
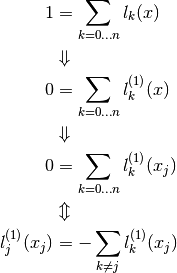
This way we have:
Theorem, Barycentric first order derivative:
Consider a set of grid values 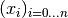 and the function values
and the function values
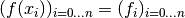 .
The formula for the first order derivative at one of the grid values
,
.
The formula for the first order derivative at one of the grid values
, 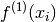 is:
is:
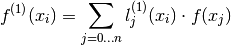
where
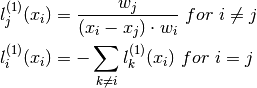
Example 1:
The formula for interpolating the first order derivative can used to
optimize the approximation of the derivative.
Consider eg 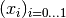 . Then
. Then
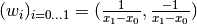 and:
and:
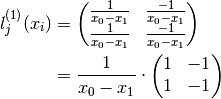
where i is the row index while j is the column index.
And then with:
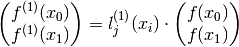
The result is:
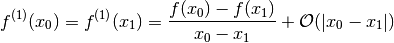
And this is the formula for Newton’s difference quotient.
Example 2:
Consider eg 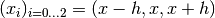 . Then
. Then 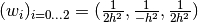 and:
and:
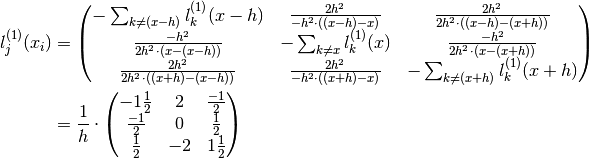
These coefficients are to formula 25.3.4 on page 883 in [AbramowitzStegun].
They are all of accuracy 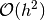 .
.
Looking at the middle row the formula for Newton’s difference quotient is found once again:
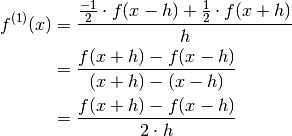
Differentiating (4) leads to:
(5)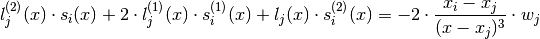
Again by design and we have for in (5):
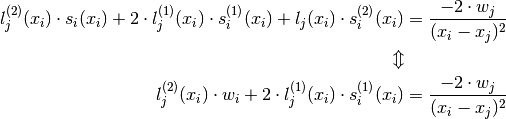
From Barycentric first order derivative Barycentric first order derivative we have
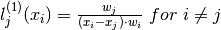 so:
so:
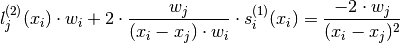
Finally since 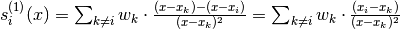 :
:
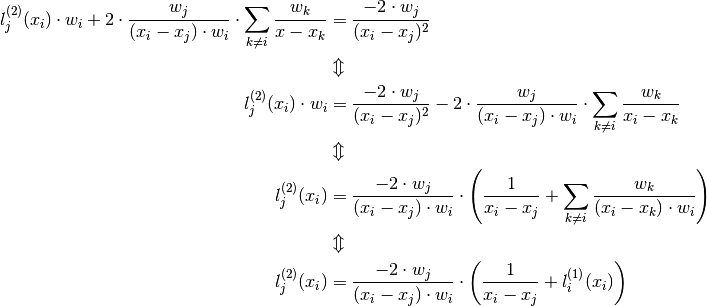
Now for i = j we have something similar as for the first order case:
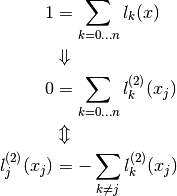
This way we have:
Theorem, Barycentric second order derivative:
Consider a set of grid values and the function values
.
The formula for the second order derivative at one of the grid values
, is:
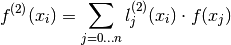
where
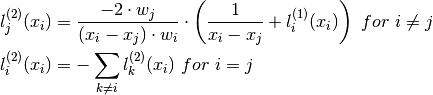
Note
There is a sign error in [BerrutTrefethen] page 513
Example 2, second order:
Consider eg . Then
and 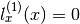 so:
so:
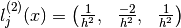
This is usual Newton second order central finite difference approximation of
accuracy 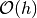 , ie:
, ie:
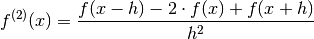
Also 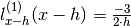 so:
so:
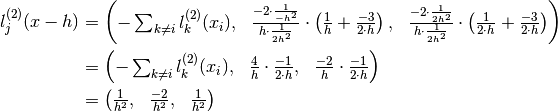
This is usual Newton second order forward finite difference approximation of
accuracy , ie:

Both results are in accordance with table 25.2 page 914 in [AbramowitzStegun].
[SadiqViswanath] study the fact that the accuracy sometimes is 1 higher than specified by Lagrange, ie the accuracy is boosted. One of their results are:
Corollary 7 page 14:
Look at the grid values 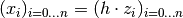 .
If the grid relative grid values
.
If the grid relative grid values 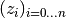 are symmetric
about 0 (in other words z is a relative grid value if and only if −z is a
relative grid value) and n − m (m is the order of the derivative) is odd,
the order of accuracy is boosted by 1.
are symmetric
about 0 (in other words z is a relative grid value if and only if −z is a
relative grid value) and n − m (m is the order of the derivative) is odd,
the order of accuracy is boosted by 1.
So according to the corollary the Newton second order central finite difference
approximation is actually of accuracy 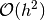 since
has symmetric relative grid
values and
since
has symmetric relative grid
values and 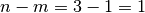 is odd.
On the other hand the accuracy of the Newton second order forward finite
difference approximation is still .
This is confirmed by table 25.2 page 914 in [AbramowitzStegun].
is odd.
On the other hand the accuracy of the Newton second order forward finite
difference approximation is still .
This is confirmed by table 25.2 page 914 in [AbramowitzStegun].
Decision, the finance package:
In the finance package the derivatives numericcally will approximated such
that the accuracy 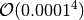 leading to an accuracy down
to the sixteenth decimal.
leading to an accuracy down
to the sixteenth decimal.
Abstract:
There is no more dangerous mathematical discipline than probability theory. And this due to the fact that intuition and actual facts differs as nowhere else.
This text goes through a list of classical probability paradoxes and it is shown that there actually are no paradoxes, only bad use of conditional probabilities.
The problems that will be studied and contrasted are:
- d’Alembert and the 2 coin tossing
- The Two Children Problem
- Getting 2 aces of the same color
- Monty Hall
- The thuesday problem
The main error is to reduce the probability space by conditioning some events away. This is first done by d’Alembert and is later done again by both Martin Gardner in “The Two Children Problem”, by Gary Foshee in “The Thuesday Child Problem” and by the opponents to vos Savant in the Monty Hall paradox.
What is done by conditioning before answering corresponds to the following. Before finding out what color an elephant has, the investigaters paints it red and then conclude that the color of the elephant is.... red.
The mistaken strategy of conditioning before answering is actually quite the oposite to modern use of conditioning in stochastic processes and filtering since here fewer events means that you know less. So in that light using the strategy of conditioning before answering you actually decide to get more ignorant before answering. And it leads to examples of fake infection of dependency.
I read about the tuesday problem in a danish e-magazine, Ingeniøren.
The problem is also described very well in Science News.
I was puzzled by the inconsistencies to my perception of probability theory. Having a master degree in applied probability theory I’ve come to learn never to trust your intuition unless you can back it up with mathematical proof and rigor.
And even then it can go wrong. As in the case of Monte Hall I’ve seen faulty probability trees used again and again to show the faulty conclusion.
And this brings me to the people that uses computer similations. Because simulations build on a wrong probability model verifies nothing just as faulty probability trees don’t prove anything.
So you seldom proves anything by a computer simulation, you just move the argument to whether or not your simulation represents the right problem.
The only way is to sit down and think the problems through throroughly.
The problem is eg described in Prakash Gorroochurn:Classic Problems of Probability, chapter 12
d’Alembert and the 2 coin tossing:
The question slightly reformulated is to calculate the probability of getting 2 tails when tossing 2 coins.
According to d’Alembert there are 3 outcomes {H, TH, TT} in which case the
probability becomes 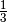 instead of the correct probability
instead of the correct probability
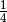 . His argument being that we don’t need to toss the second
coin when the first is Head.
. His argument being that we don’t need to toss the second
coin when the first is Head.
Actually he is answering the question by conditioning. Letting T1 and T2 being
the events of having tail in toss 1 and 2 respectively his answer is
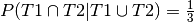
And hence d’Alembert is assigning a wrong probability to the outcome H by ignoring the outcomes of the second coin. And hence he is coming to the wrong result by reducing probability space by conditioning on it before answering.
Today everyone agrees that d’Alembert is wrong by not using the full and original probability space {HH, TH, HT, TT}, but at the time he actually had what appeared to be the best arguments.
But this classical error appears again and again in the so called paradoxes below.
We continue with The Two Children Problem.
This is also analyzed in eg Grinstead and Snell’s Introduction to Probability p. 171
The Two Children Problem:
Suppose that Mr. Smith has two children, at least one of whom is a son. What is the probability both children are boys?
Let us to start by looking at the probability space of 2 children and whether or not each child is a boy (B) or a girl (G).
Here we have the events (where i is the order the children are born):
- B1, B2 is the event that child number 1, 2 is a boy, respectively
- G1, G2 is the event that child number 1, 2 is a girl, respectively
and BR is short for 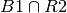 .
.
The probabilities are:
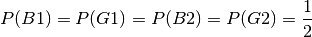
The 2 events B1 and B2 are assumed to be independent.
To answer the question we say that in the frase “at least one of whom is a son” we don’t know whether it is the oldest or the youngest child that is that boy mentioned.
Now given that the boy is the oldest then the probability for him to have a
younger brother is due to independence 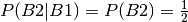 .
.
And hence by similarity:
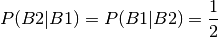
Combining this gives :
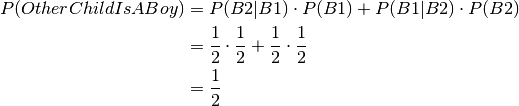
In other words: If we know which child we’ve got the information about, then the
sex of the other child remains independent of the first childs sex.
And hence the the probability of the other child being a boy is
. Since we do not which child the information is about we
have to take the “average” of the probabilities of the other child being a boy
over child chosen. Still independence is preserved.
So we keep the assumption that the sex of each child is independent of the other.
This result fits into the intuition since knowing the sex of one child shouldn’t influence the probability of the other child.
The other way of looking at it is the one of Gardner’s and the referred to in Ingeniøren. It is similar to the the way d’Alembert wrongfully solved his problem.
They are saying given that there is at least 1 boy out of 2 children
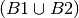 what is the probability of having 2 boys
what is the probability of having 2 boys
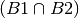 .
.
So they interpret the answer as a conditional probability
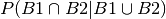 .
.
The probability of at least 1 boy is:
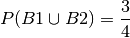
And then the answer becomes:
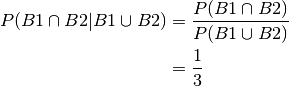
But conditioning changes the probability space totally as can be seen by:
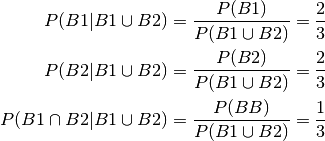
which shows that B1 and B2 no more are independent since:
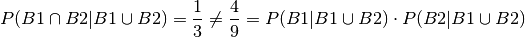
This fact becomes the key to handling the thuesday problem later on.
So by conditioning by one makes to 2 originally independent
events B1 and B2 dependent.
There is nothing mathematically wrong in the above.
In the end it is all a matter of whether 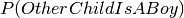 or
is the answer to the question.
or
is the answer to the question.
But as noted beforeit is easy to see that the answer
is making the same mistake as d’Alembert.
At this point it might be an good idea to dwell at what conditioning actually means?
By conditioning you reduce the originally probability space to a new probability space.
Since the events in the conditioned probability space is a subset of the originally space one would expect that other bindings like independence are inherited, but they aren’t necessarily.
But it is a new probability space where the event GG never happens (just like d’Alembert paradox) whenever someone is talking about being parent to 2 children.
And that is why the conditioned probability space shouldn’t be used in answering the question.
On the other hand it is quite easy to consider the situation where you meet a person and one of his/hers children.
Looking closer you see that the accompanying child is a boy. From the conversation following it appears that he/she has another child.
In this case the probability of him/her having 2 boys when it is known that
he/she has at least one boy is 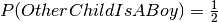 .
.
The next case shows how one sometimes can be mislead by using uniform probabilities instead of the right ones. But conditioning to get the answer can also be a mistake.
Drawing 2 cards of the same color out of 4 cards:
Draw 2 cards from 4 cards, eg 4 aces. What are the probability of drawing 2 of the same color (2 reds or 2 blacks)?
Here we have the events:
- B1, B2 is the event that card number 1, 2 is black, respectively
- R1, R2 is the event that card number 1, 2 is red, respectively
and BR is short for
Here one can be mislead to believe that there are 4 events {BB, BR, RB, RR} with equal probability leading to the (wrong) answer:

But the probabilities are in fact:
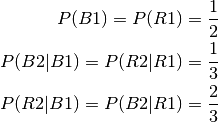
leading to:
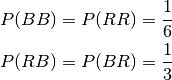
Here the right answer is 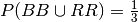
The not so known mistake however is to argue for the right probability by using P(B2|B1) or P(R2|R1). This is only right due to symmetry.
If there were 5 cards (3 reds and 2 blacks) one would get the probabilities:
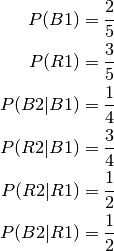
Here the 2 conditional distributions are very different since one conditioning on R1 is uniform. So here one can’t use P(B2|B1) or P(R2|R1) directly.
Now the above leads to:
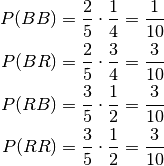
Here the right answer becomes 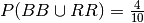 , which is
neither
, which is
neither 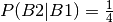 or
or 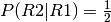 .
.
So of course one should use the right underlying probabilities, but one should also be carefull about answering in the full probability space.
Here it is again a question of posing the right questions in order to build the right probability space. Also here You don’t answer the question by conditioning the probability space before answering.
Suppose you’re on a game show, and you’re given the choice of three doors: Behind one door is a car; behind the others, goats. You pick a door, say No. 1, and the host, who knows what’s behind the doors, opens another door, say No. 3, which has a goat. He then says to you, “Do you want to pick door No. 2?” Is it to your advantage to switch your choice?
The faulty solution says that after a door is opened then there are 2 doors with equal probability. And hence there is no gain in choosing the other door.
Here the originally probability space is reduced by the one door opened.
Proper analysis eg in Grinstead and Snell’s Introduction to Probability, p. 136
shows that the proper probability is 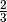 if you choose the other
door.
if you choose the other
door.
The argument being based of the originally probability space with 3 doors is shown below.
The columns represents the 3 independent events that describes the whole probability space:
The probability space is:
| Car behind door | Door Chosen | Monty opens | Path Probability | Choose other door |
|---|---|---|---|---|
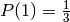 |
|
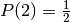 |
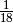 |
Loose |
|
|
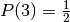 |
|
Loose |
|
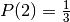 |
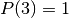 |
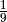 |
Win |
|
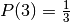 |
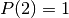 |
|
Win |
|
|
|
|
Win |
|
|
|
|
Loose |
|
|
|
|
Loose |
|
|
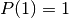 |
|
Win |
|
|
|
|
Loose |
|
|
|
|
Loose |
|
|
|
|
Win |
|
|
|
|
Win |
And hence we have 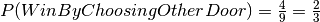 and
then it is better to choose the other door.
and
then it is better to choose the other door.
Now we are ready for the Thuesday Child Problem. It is an expansion of the 2 children paradox above.
The Thuesday Child Problem:
Suppose that a person has two children, at least one of whom is a son born on a Thuesday. What is the probability both children are boys?
One should imagine that the information on which day the child was born was irrelevant. But when conditioning on the probability space before answering one by accident introduces a false dependency between birth day of week and the sex of the child and hence some change in the probabilities.
As seen at 2 Children Paradox this is the wrong way to answer the question. After showing the wrong arguments leading to the paradox, the right way to do the calculations are shown.
Finally I show how adding more and more irrelevant information actually leads to a convergence to the right probability.
First some notation. There are 2 children, 1 is short for the oldest and 2 is short of the youngest. Each child can be a boy (B) or a girl (G). Finally each child can be born on a Thuesday (T) or at any other day of the week (O).
It is assumed that child order, child sex and child birth day are independent.
In short:
- 1G is first child is a girl
- 1T is first child is born on a Thuesday
- 1BT is first child is a boy born on a Thuesday
- 1BT2GO is first child is a boy born on a Thuesday and second child is a girl born on any other day than Thuesday
- etc.
And the basic probabilities are:
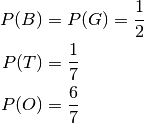
As in the 2 Children Problem we choose to ignore all events not having at least
one boy born on a Thuesday as an event, ie we condition with 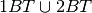 .
.
Below is a probability summary:
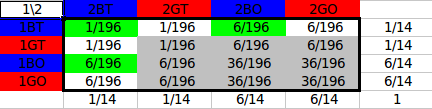
Now:
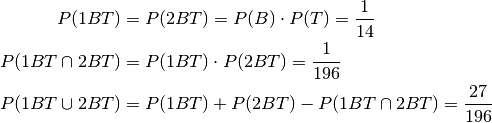
This is anything but the grey area in the probability summary.
And the probability of 2 boys, ie the other child is a boy, at least one of them born on a Thuesday is:
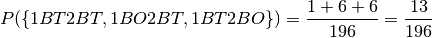
This is the green area in the probability summary.
And hence (ignoring the grey area):
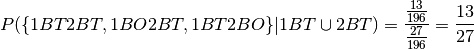
So the probability of the other child 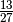 , a little less than
the right value and actually quite far from the
that would be expected from the 2 Children Problem.
, a little less than
the right value and actually quite far from the
that would be expected from the 2 Children Problem.
Let us add a paradox to the paradox. Now what happens if we didn’t knew P(T), but set it to p. Then P(O) = 1 - p.
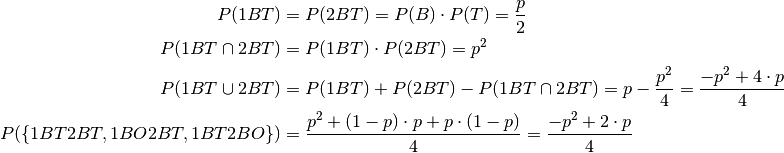
This leads to:
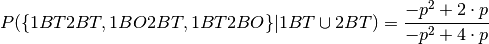
Now if we make the event more rare, eg saying that the child was born on aprils
fool, then p would become smaller, eg 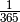 . Then we see that:
. Then we see that:
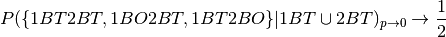
Which can be seen easily by the use of the rule of l’Hospital.
Now making the event more rare corresponds to adding more and more irrelevant data, ie noise.
And what is seen from the above limit is that the more noise that is added the
closer we get to the right probability (not the wrong
probability from the 2 Children Problem, ).
Actually the function 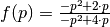 is monotone decreasing in the interval [0, 1] and the minimum
is monotone decreasing in the interval [0, 1] and the minimum
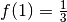 .
.
So the probability of the other child being a boy too is dependent on the amount
of noice added. And in the one extreme case of no noice we get the Gardner case,
and in the other extreme of total noice we get the
probability from independency of sexes, .
This makes no sence! The probability should be constant, ie independent of noice. And it is constant if calculations are done properly!
Let us see how one should do the calculations. The argument is similar to the 2 Children problem.
If we known which child who is the thuesday boy then the answer is simple since the sex of the other child is independent of whatever can be said about the thuesday child.
Define 1BT, 2BT as the event that child 1, 2 is the thuesday boy, respectively.
And since the children are chosen randomly we have
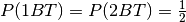 .
.
And then we have:
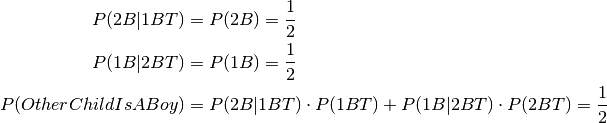
I rest my case :)